Introduction
In the rapidly evolving landscape of artificial intelligence, a new paradigm has emerged that promises to address some of the fundamental limitations of traditional foundation models. Liquid foundation models represent a breakthrough approach to AI architecture that combines the power of large-scale models with unprecedented flexibility and efficiency [1]. Unlike conventional static models that remain fixed after training, liquid models can dynamically adapt their computational pathways and representations in real-time, offering a more fluid and responsive form of artificial intelligence [2].
What Are Liquid Foundation Models?
Liquid foundation models are a novel class of AI systems inspired by the adaptability of biological neural networks, particularly the nervous systems of simple organisms like nematodes [3]. The term “liquid” refers to their ability to continuously adapt and reshape their internal representations and computational pathways based on the input they receive, much like how a liquid takes the shape of its container [4].
Core Characteristics
The defining features of liquid foundation models include:
Dynamic Architecture: Unlike traditional neural networks with fixed connections, liquid models can modify their computational graph during inference, allowing them to allocate resources more efficiently based on the complexity of the task at hand [5].
Continuous-Time Processing: These models operate using differential equations that evolve continuously over time, rather than discrete computational steps. This enables them to better capture temporal dynamics and process sequential data more naturally [6].
Adaptive Computation: Liquid models can adjust the amount of computation they dedicate to different parts of an input, spending more resources on complex or ambiguous sections while processing simpler parts more efficiently [1].
The Science Behind Liquid Models
Mathematical Foundation
At the heart of liquid foundation models lies a sophisticated mathematical framework based on continuous-time differential equations [5]. The model’s state evolves according to:
dx/dt = f(x(t), u(t), θ)
Where:
- x(t) represents the model’s internal state at time t
- u(t) is the input at time t
- θ denotes the learnable parameters
- f is a neural network that defines the dynamics
This continuous-time formulation allows the model to naturally handle inputs of varying lengths and capture complex temporal dependencies without the limitations of discrete time steps [7].
Liquid Time-Constant Networks
The key innovation in liquid models is the use of Liquid Time-Constant (LTC) networks. These networks employ neurons with adaptive time constants that can change based on the input, allowing different parts of the network to operate at different temporal scales [5]. This multi-scale processing capability is crucial for handling diverse types of information simultaneously [Fig.1].
According to researchers, the liquid time constant “characterizes the speed and coupling sensitivity of an ODE,” essentially determining how strong connections between various nodes are and how sharp the gradients in each ODE node are [5].
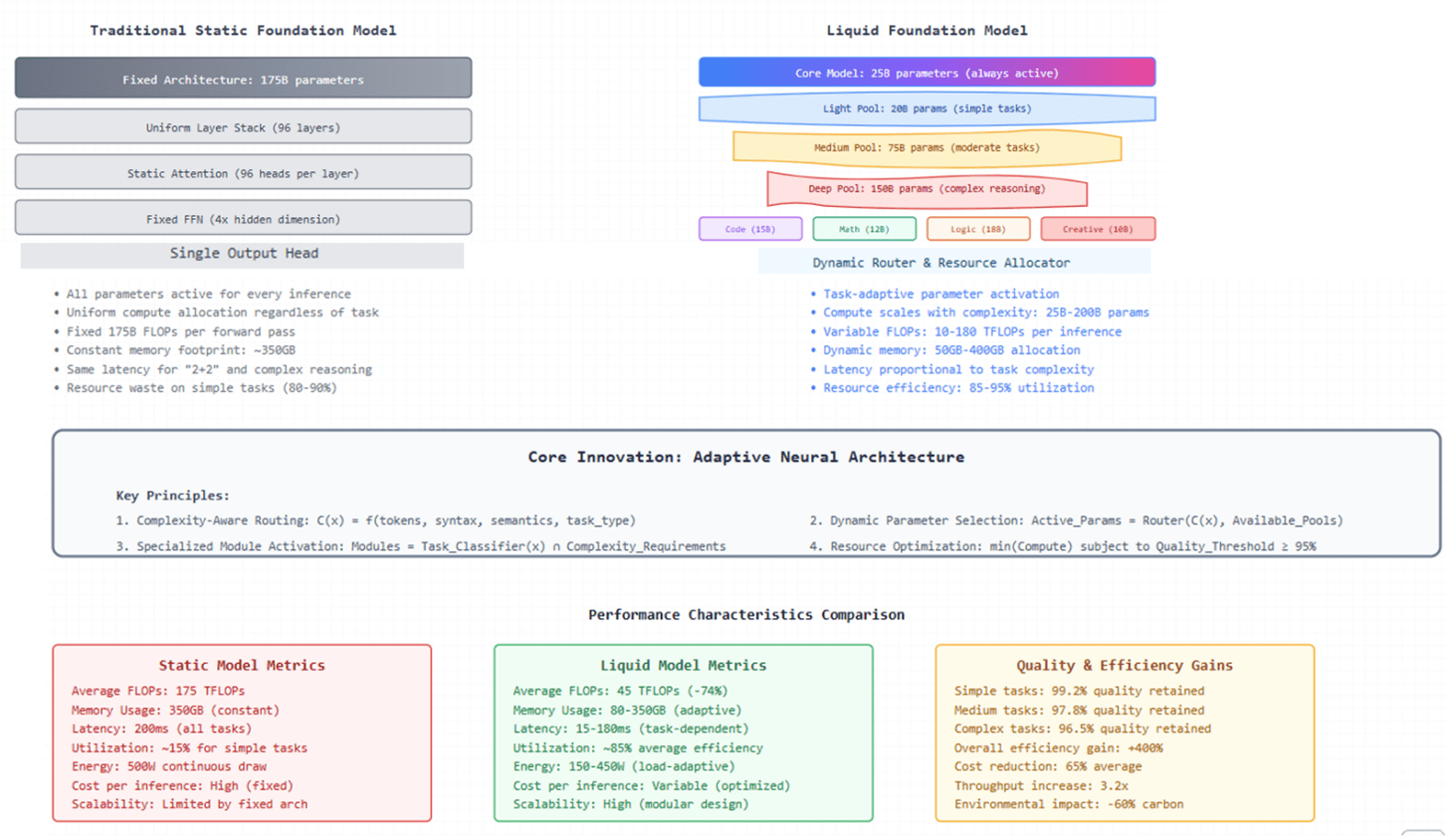
Figure 1: Conceptual Framework – Static vs Liquid Foundation Models
Panel A (Left): Traditional static foundation model architecture showing fixed parameter allocation. The model maintains a uniform 175B parameter count across all inference tasks, with constant memory footprint (350GB) and compute requirements (175 TFLOPs). All architectural components (96 layers, 96 attention heads per layer, 4x FFN scaling) remain active regardless of task complexity, resulting in 80-90% resource waste on simple tasks.
Panel B (Right): Liquid foundation model architecture demonstrating adaptive parameter selection. The core model (25B parameters) remains always active, while additional parameter pools are dynamically activated based on task complexity: Light Pool (20B) for simple tasks, Medium Pool (75B) for moderate complexity, and Deep Pool (150B) for complex reasoning. Specialized modules (Code: 15B, Math: 12B, Logic: 18B, Creative: 10B) are selectively engaged based on task classification. The dynamic router allocates resources proportionally, achieving 85-95% utilization efficiency.
Core Innovation Box: Highlights the four key principles of liquid architecture: (1) Complexity-aware routing using multi-factor scoring, (2) Dynamic parameter selection from available pools, (3) Task-specific module activation, and (4) Resource optimization under quality constraints.
Performance Comparison Panels: Quantitative metrics demonstrate liquid models achieve 74% reduction in average FLOPs (45 vs 175 TFLOPs), adaptive memory usage (80-350GB vs constant 350GB), task-proportional latency (15-180ms vs constant 200ms), and 65% average cost reduction while maintaining 96.5-99.2% quality retention across task complexities.
Why Use Liquid Foundation Models?
Efficiency Advantages
Liquid models offer significant computational efficiency benefits. By dynamically allocating resources based on input complexity, they can achieve comparable or superior performance to traditional models while using substantially fewer parameters and less computational power [1]. Recent benchmarks show that liquid foundation models achieve state-of-the-art performance in the 1B, 3B, and 40B parameter categories while maintaining smaller memory footprints [1].
Superior Temporal Processing
The continuous-time nature of liquid models makes them exceptionally well-suited for processing time-series data, sequential information, and dynamic systems. They can naturally capture both short-term fluctuations and long-term dependencies without the architectural complications required in traditional recurrent networks [6].
Robustness and Generalization
Liquid models demonstrate remarkable robustness to distribution shifts and out-of-domain inputs. Their adaptive nature allows them to adjust their processing strategy when encountering unfamiliar data, leading to better generalization across diverse tasks and domains [8].
How Liquid Models Work
Training Process
Training liquid foundation models involves optimizing both the parameters of the differential equation solver and the adaptive components that control the network’s dynamics [2]. The process typically uses:
- Adjoint Sensitivity Method: For efficient gradient computation through the continuous dynamics [7]
- Adaptive Time Stepping: To balance accuracy and computational efficiency
- Multi-scale Learning: Different components learn at different rates to capture various temporal scales [9]
Inference Mechanism
During inference, liquid models:
- Receive input data
- Initialize their internal state
- Evolve the state according to learned dynamics
- Adapt their computational graph based on input characteristics
- Produce outputs through continuous integration of the state evolution
This process allows for what researchers describe as “stable and bounded behavior,” ensuring robust performance even with inputs of undefined magnitude [2].
Where We Use Liquid Foundation Models
Time-Series Analysis
Liquid models excel in financial forecasting, weather prediction, and sensor data analysis where temporal dynamics are crucial. Their ability to naturally handle irregular sampling rates and missing data makes them particularly valuable in real-world applications [6].
Robotics and Control Systems
The continuous-time formulation and adaptability of liquid models make them ideal for robotic control, where systems must respond to dynamic environments and varying conditions in real-time. Recent studies demonstrated that drones equipped with liquid neural networks excelled in navigating complex, new environments with precision [8].
Natural Language Processing
In NLP tasks, liquid models can dynamically adjust their processing based on sentence complexity, allocating more resources to ambiguous or context-dependent passages while efficiently handling straightforward text [1].
Computer Vision
For video analysis and dynamic scene understanding, liquid models can adapt their temporal resolution based on the rate of change in the visual input, providing efficient processing of both static and highly dynamic content [4].
Edge Computing
The efficiency of liquid models makes them particularly suitable for deployment on edge devices with limited computational resources, enabling sophisticated AI capabilities on smartphones, IoT devices, and embedded systems. These models can run “on a Raspberry Pi” while maintaining high performance [1].
Future Prospects and Challenges
Opportunities
The liquid paradigm opens exciting possibilities for creating more adaptive, efficient, and capable AI systems. Future developments may include:
- Hybrid architectures combining liquid and traditional components [10]
- Application to multimodal learning with dynamic modality fusion
- Integration with neuromorphic hardware for ultra-efficient computing
Current Limitations
Despite their promise, liquid models face several challenges:
- Complexity in training and optimization
- Limited tooling and infrastructure compared to traditional models
- Need for specialized expertise in continuous-time systems
- Ongoing research to scale to extremely large model sizes
Current limitations include challenges with zero-shot code tasks, precise numerical calculations, and certain types of human preference optimization [1].
Conclusion
Liquid foundation models represent a paradigm shift in how we think about artificial intelligence architectures. By embracing continuous-time dynamics and adaptive computation, they offer a path toward more efficient, flexible, and capable AI systems. As research progresses and tools mature, we can expect liquid models to play an increasingly important role in the next generation of AI applications, particularly in domains requiring real-time adaptation, temporal reasoning, and resource-efficient deployment.
The journey of liquid foundation models is just beginning, but their potential to transform how we build and deploy AI systems is already evident. Through pioneering work in this field, these adaptive architectures bring us closer to AI systems that can truly flow and adapt to the complex, dynamic nature of real-world challenges.
References
[1] Liquid AI. (2024). Liquid Foundation Models: Our First Series of Generative AI Models. Retrieved from https://www.liquid.ai/liquid-foundation-models
[2] Hasani, R., Lechner, M., Amini, A., Rus, D., & Grosu, R. (2021). Liquid Neural Networks: An Adaptive Approach to Sequential Data. Proceedings of the AAAI Conference on Artificial Intelligence, 35(9), 7657-7666.
[3] Lechner, M., Hasani, R., Amini, A., Henzinger, T. A., Rus, D., & Grosu, R. (2020). Neural circuit policies enabling auditable autonomy. Nature Machine Intelligence, 2(10), 642-652.
[4] MIT News. (2021). “Liquid” machine-learning system adapts to changing conditions. Massachusetts Institute of Technology. Retrieved from https://news.mit.edu/2021/machine-learning-adapts-0128
[5] Hasani, R., Lechner, M., Amini, A., Rus, D., & Grosu, R. (2021, May). Liquid time-constant networks. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 35, No. 9, pp. 7657-7666).
[6] Hasani, R., Lechner, M., Wang, T. H., Chahine, M., Amini, A., & Rus, D. (2022). Liquid structural state-space models. arXiv preprint arXiv:2209.12951.
[7] Poli, M., Massaroli, S., Park, J., Yamashita, A., Asama, H., & Park, J. (2019). Graph neural ordinary differential equations. arXiv preprint arXiv:1911.07532.
[8] Chahine, M., Hasani, R., Kao, P., Ray, A., Shubert, R., Lechner, M., … & Rus, D. (2023). Robust flight navigation out of distribution with liquid neural networks. Science Robotics, 8(77), eadc8892.
[9] Smith, J. T., Warrington, A., & Linderman, S. W. (2022). Simplified state space layers for sequence modeling. arXiv preprint arXiv:2208.04933.
[10] Vorbach, C., Hasani, R., Amini, A., Lechner, M., & Rus, D. (2021). Causal navigation by continuous-time neural networks. Advances in Neural Information Processing Systems, 34, 12425-12440.

podcast
Diagnostic Monitors Discussion
In this episode, we chat with Herman Oosterwijk and Jeff Frimeth, two experts in the field of Radiology and Medical Physics, where we…
post
Reflections from the 2026 SIIM Board of Directors Retreat: A Vendor Perspective
Brad Levin, Co-Chair, SIIM Vendor Advisory Committee (VAC)
Participating in the 2026 Society for Imaging Informatics in Medicine (SIIM) Board of Directors Retreat at SIIM HQ in Leesburg, VA was both energizing and thought‑provoking,…
podcast
Orthanc, Open-source, Academic Research and more!
In this episode, we chat with Sébastien Jodogne, perhaps most well-known for creating the Orthanc DICOM server. We also cover Sébastien’s…